Introdução
- Processador: 1 vCPU com clock acima de 2.0 GHz.
- Memória: 1 GB.
- HD1: 50 GB (com duas partições: / de 42 GB e swap de 8 GB).
- HD2: 20 GB (mas este não foi configurado durante a instalação do S.O).
- 2 placas de rede.
- S.O: Red Hat 6.8 64 bits com idioma em Inglês-US (UTF-8).
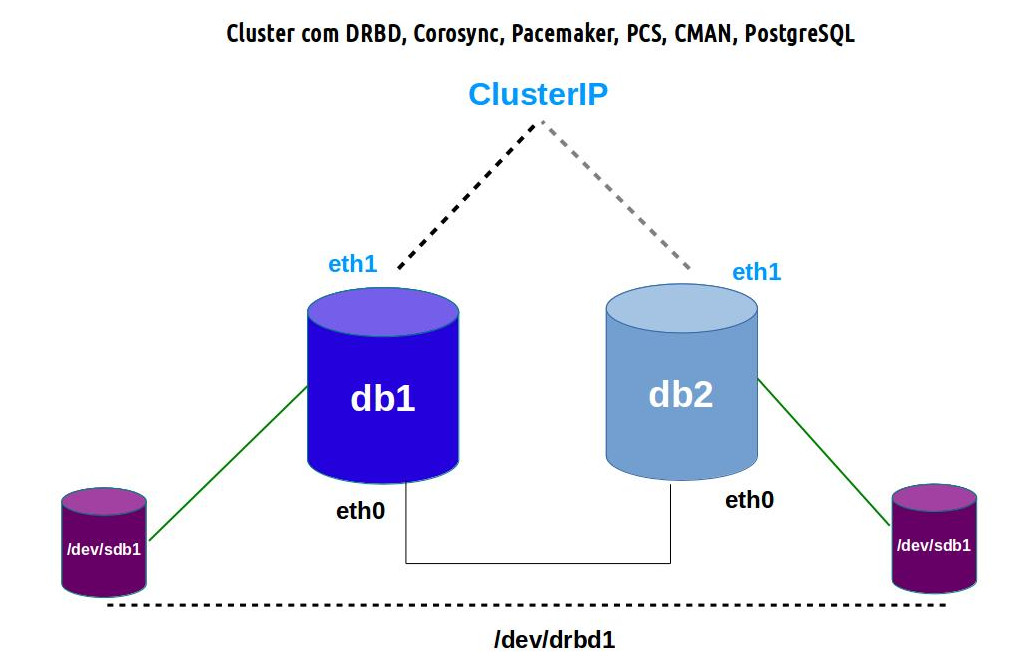
Cada VM possui duas placas de rede, mas apenas uma das placas de rede de cada VM foi configurada com IP fixo (também pode ser usado IPs distribuídos pelo serviço DHCP, desde que os IPs sejam associados ao MAC de uma placa de rede de cada VM).
- db1.domain.com.br: 10.0.0.1/24 na interface eth0
- db2.domain.com.br: 10.0.0.2/24 na interface eth0
Estas informações foram adicionadas no arquivo /etc/hosts de cada máquina. Veja o ambiente do cluster na figura abaixo.
Após a instalação do S.O, é necessário que ele esteja registrado para poder acessar os repositórios oficiais da Red Hat. Veja nesta página como registrar o sistema: https://access.redhat.com/documentation/en-US/Red_Hat_Network_Satellite/5.3/html/Reference_Guide/ch-register.html
Instalação dos pacotes
Aviso: Os passos abaixo devem ser executados nas duas máquinas.
1- Crie o arquivo /etc/yum.repos.d/centos.repo e adicione o seguinte conteúdo.
[centos-6-base]
name=CentOS-$releasever
Base mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=os
baseurl=http://mirror.globo.com/centos/6.8/os/x86_64/
enabled=1
rpm -Uvh http://www.elrepo.org/elrepo-release-6-6.el6.elrepo.noarch.rpm rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org rpm --import http://mirror.globo.com/centos/6.8/os/x86_64/RPM-GPG-KEY-CentOS-6 rpm -ivh https://download.postgresql.org/pub/repos/yum/9.3/redhat/rhel-6-x86_64/pgdg-redhat93-9.3-2.noarch.rpm
3- Execute o comando abaixo para instalar os pacotes que usaremos ao longo do tutorial.
yum -y install pacemaker cman pcs ccs resource-agents ntsysv kmod-drbd84 drbd84-utils postgresql93-contrib postgresql93 postgresql93-server
Cada nó terá os seguintes componentes de software, a fim de trabalhar como membro do o cluster HA (High-availability).
Pacemaker => É um gestor de recursos do cluster, que executa scripts no momento em que os nós do cluster são inicializados ou desligados ou quando os recursos relacionados falham. Além disso, pode ser configurado para verificar periodicamente o estado de cada nó do cluster. Em outras palavras, o pacemaker será encarregado de dar a partida e parada dos serviços (como um servidor web ou de banco de dados, para citar um exemplo clássico) e irá implementar a lógica para garantir que todos os serviços necessários estão rodando em apenas um local, ao mesmo tempo a fim de evitar a corrupção de dados.
Corosync: Trata-se de um serviço de mensagens que irá fornecer um canal de comunicação entre os nós do cluster. Ele é essencial e funciona como um marca-passo que checa a disponibilidade de cada nó.
PCS: É uma ferramenta de configuração do corosync e pacemaker que permite a visualização, edição e criação de clusters. Ele é opcional, mas é bom instalá-lo para ajudar na configuração do Cluster.
Desabilitando o Selinux e Iptables
Como este tutorial tem objetivo apenas de criar um ambiente de teste, desabilite o SELinux e o Iptables para não interferir na comunicação dos nodes do cluster e na configuração dos serviços.
Configurando os dois nós do cluster para sincronizar a configuração
Em cada máquina virtual foram executados os comandos abaixo, para iniciar o serviço pcsd e definir uma senha para o usuário hacluster, que será usado futuramente para sincronizar a configuração do cluster nas duas VMs. A senha do usuário hacluster deve ser a mesma em cada máquina.
service pcsd start
passwd hacluster
Adicionando os nós do cluster
Na VM db1, foram executados os comandos abaixo para adicionar os nós do cluster.
pcs cluster auth db1 db2
pcs cluster setup --name cluster-db db1 db2
pcs cluster start --all
OBS.: Durante a execução dos comandos será solicitado o login e senha do usuário hacluster.
Os comandos abaixo configuram algumas das propriedades principais do cluster.
pcs property set stonith-enabled=false
pcs property set no-quorum-policy=ignore
pcs resource defaults migration-threshold=1
corosync-cfgtool -s
corosync-cpgtool
pcs status
service pcsd start
service corosync start
service cman start
service pacemaker start
Configure os serviços para serem inicializados no boot do S.O das duas máquinas
chkconfig pcsd on
chkconfig cman on
chkconfig pacemaker on
chkconfig corosync on
Visualizando a configuração do cluster
Quando quiser visualizar a configuração do cluster, use o comando abaixo.
pcs config
Comando para remoção da configuração do cluster
Se precisa remover a configuração do cluster, use os comandos abaixo nas duas VMs.
pcs cluster stop --force pcs cluster destroy
Adicionando o IP do cluster como um recurso
Na VM db1 foi executado o comando abaixo para configurar o IP do cluster.
pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.0.1 cidr_netmask=24 nic=eth1 op monitor interval=10s
Execute o comando abaixo para visualizar a configuração.
ifconfig
Testando a migração do IP do cluster para a máquina db2. Na máquina db1 execute:
pcs cluster stop db1 --force
Na máquina db2, execute o comando abaixo para visualizar a configuração.
ifconfig
Na máquina db1, inicie o cluster.
pcs cluster start db1
Novamente execute o comando abaixo para visualizar a configuração.
ifconfig
Adicionando uma rota de saída do cluster como um recurso
Na VM db1 foi executado o comando abaixo para configurar a rota do cluster. É por essa rota que o cluster irá se comunicar com os hosts das demais redes.
pcs resource create DefRoute ocf:heartbeat:Route destination=default device=eth1 gateway=192.168.0.1 op monitor interval=10s
Adicionando um grupo de recursos
Para evitar que os recursos ClusterIP e DefRoute sejam iniciados em máquinas diferentes do cluster, podemos criar um grupo de recursos e incluí-los de forma que os dois sejam iniciados na mesma máquina. Para fazer isto, use os comandos abaixo:
pcs resource group add ClusterGrupoRecursos ClusterIP DefRoute
pcs resource manage ClusterIP DefRoute
Listando, atualizando e removendo um recurso
Se precisar listar os recursos ativos do cluster, use o comando abaixo.
pcs resource show
pcs resource update ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.0.75 cidr_netmask=24 nic=eth1 op monitor interval=10s
Se precisar remover um recurso do cluster, use o comando abaixo.
pcs resource delete NOMERECURSO
pcs resource cleanup NOMERECURSO
Se precisar ver a inicialização de um recurso no modo debug (depuração), use o comando abaixo:
pcs resource debug-start NOMERECURSO --full
Fonte: http://clusterlabs.org/doc/en-US/Pacemaker/1.1/html-single/Pacemaker_Explained/#ap-lsb
Se precisar consultar a lista de agentes do heartbeat, pacemaker ou LSB para configurar um recurso do cluster, use os comandos abaixo.
pcs resource agents ocf:heartbeat
pcs resource agents ocf:pacemaker
pcs resource agents lsb:
Configurando o DRBD nas duas máquinas
Os pacotes do DRBD já foram instalados no início do tutorial.
As duas VMs já possuem um segundo disco de 20 GB e que não foi usado durante a instalação. Esses discos serão usados pelo serviço DRBD para sincronizar os dados. O DRBD atuará como um cluster Ativo > Passivo. Os dados serão gravados apenas na máquina ativa do cluster. Na máquina passiva os dados serão sincronizados e o disco ficará apenas no modo leitura. O disco a ser usado pelo DRBD será montado no sistema como /database com o sistema de arquivos ext4 e será usado pelo PostgreSQL para armazenar os arquivos dos bancos de dados.
Em cada máquina, crie o arquivo /etc/drbd.d/disk_database.res com o conteúdo abaixo para configurar um recurso no DRBD que usará o disco disponível identificado no S.O como /dev/sdb1.
resource disk_database {
protocol C;
meta-disk internal;
device /dev/drbd1;
syncer {
verify-alg sha1;
}
net {
allow-two-primaries;
}
on db1 {
disk /dev/sdb;
address 10.0.0.1:7789;
}
on db2 {
disk /dev/sdb;
address 10.0.0.2:7789;
}
}
O disco /dev/drdb1, configurado acima, é o disco DRBD que abstraí o uso do disco /dev/sdb1 de cada máquina.
Em cada máquina, ative o uso do recurso com os comandos abaixo.
drbdadm create-md disk_database
modprobe drbd
drbdadm up disk_database
Na máquina db1, force-a para ser o nó primário do DRBD.
drbdadm primary --force disk_database
cat /proc/drbd
Quando terminar a sincronização dos discos, execute o comando abaixo na máquina db1 para formatá-lo com o sistema de arquivos ext4.
mkfs.ext4 /dev/drbd1
mkdir /database
mount /dev/drbd1 /database
ls /database
mkdir /database/teste
touch /database/teste/a.txt
Configurando o DRBD para ser gerenciado pelo cluster
Na máquina db1, execute os comandos abaixo para configurar o recurso DRBD disk_database (configurado no arquivo /etc/drbd.d/disk_database.res) para ser gerenciado pelo Cluster.
pcs cluster cib drbd_cfg
pcs -f drbd_cfg resource create DBData ocf:linbit:drbd \
drbd_resource=disk_database op monitor interval=60s
pcs -f drbd_cfg resource master DBDataClone DBData \
master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
Execute o comando abaixo para visualizar a configuração do recurso.
pcs -f drbd_cfg resource show
Execute o comando abaixo para salvar e habilitar a configuração do recurso.
pcs cluster cib-push drbd_cfg
Execute o comando abaixo para visualizar a configuração do cluster
pcs status
Habilite nas duas máquinas, o carregamento do módulo drbd no boot do S.O.
echo drbd > /etc/modprobe.d/drbd.conf
Configurando o Postgresql
mkdir -p /database/pgsql
chown -R postgres:postgres /database/
chmod -R 0700 /database/
sudo -u postgres /usr/pgsql-9.3/bin/initdb -D /database/pgsql
PGPORT=5433
PGDATA=/database/pgsql/
PGLOG=/database/pgsql/pgstartup.log
PGUPLOG=/database/pgsql/pgupgrade.log
scp /etc/init.d/postgresql-9.3 root@db2:/etc/init.d/postgresql-9.3
Configurando recurso Postgresql no cluster
Na máquina db1, execute o comando abaixo para criar o recurso Postgresql que irá inicializar o serviço na máquina ativa do cluster, usando o script /etc/init.d/postgresql-9.3 (representado no comando abaixo por lsb:postgresql-9.3). É importante lembrar que ele não deve ser inicializado junto com o boot do sistema operacional. Apenas o cluster deve inicializá-lo.
pcs resource create Postgresql lsb:postgresql-9.3
Configurando a ordem de inicialização dos recursos no cluster
Configure o cluster para só inicializar o Postgresql depois de configurar o IP, a rota e montar o disco /dev/drbd1 em /database (usando o sistema de arquivos ext4) na máquina ativa. Execute os comandos abaixo apenas na máquina db1, pois a configuração será replicada para o db2.
pcs cluster cib fs_cfg
pcs -f fs_cfg resource create DBFS Filesystem \
device="/dev/drbd1" directory="/database" fstype="ext4"
pcs -f fs_cfg constraint colocation add DBFS with DBDataClone INFINITY with-rsc-role=Master
pcs -f fs_cfg constraint order promote DBDataClone then start DBFS
pcs -f fs_cfg constraint colocation add ClusterIP with DefRoute INFINITY
pcs -f fs_cfg constraint order ClusterIP then DefRoute
pcs -f fs_cfg constraint colocation add DefRoute with DBFS INFINITY
pcs -f fs_cfg constraint order DefRoute then DBFS
pcs -f fs_cfg constraint colocation add Postgresql with DBFS INFINITY
pcs -f fs_cfg constraint order DBFS then Postgresql
Execute os comandos abaixo para revisar a configuração.
pcs -f fs_cfg constraint
pcs -f fs_cfg resource show
Execute o comando abaixo para salvar e habilitar a configuração do recurso.
pcs cluster cib-push fs_cfg
Execute o comando abaixo para visualizar a configuração do cluster
pcs status
/etc/init.d/postgresql-9.3 status
Comandos úteis à gerência de configuração do cluster
pcs cluster cib --config pcs cluster cib
pcs config backup cluster_config_$(date +%Y-%m-%d)
Restaurando a configuração do cluster a partir do backup:1) Você precisa parar o serviço de cluster no nó, restaurar a configuração e iniciá-lo depois:
pcs cluster stop node --force pcs config restore --local cluster_config_$(date +%Y-%m-%d).tar.bz2 pcs cluster start node
pcs cluster stop node --force pcs config restore cluster_config_$(date +%Y-%m-%d).tar.bz2 pcs cluster start node
pcs cluster report [--from "YYYY-M-D H:M:S" [--to "YYYY-M-D" H:M:S"]]" dest
pcs config checkpoint
pcs config checkpoint view <checkpoint_number>
pcs config checkpoint restore <checkpoint_number>
Fontes:
Livros:
https://www.packtpub.com/networking-and-servers/centos-high-availability
https://www.packtpub.com/networking-and-servers/centos-high-performance
http://www.apress.com/9781484200803
https://www.suse.com/documentation/sle-ha-12/singlehtml/book_sleha/book_sleha.html
https://www.packtpub.com/big-data-and-business-intelligence/postgresql-9-high-availability-cookbook
http://blog.clusterlabs.org/blog/2010/pacemaker-heartbeat-corosync-wtf/
http://www.unixmen.com/configure-drbd-centos-6-5/
http://clusterlabs.org/quickstart-redhat-6.html
http://elrepo.org/tiki/tiki-index.php
http://drbd.linbit.com/en/doc/users-guide-84
CRMSH vs PCS: https://github.com/ClusterLabs/pacemaker/blob/master/doc/pcs-crmsh-quick-ref.md
http://www.picoloto.com.br/tag/mkfs-ext4
http://asilva.eti.br/instalar-cluster-high-availbility-no-centos-7-com-pacemaker/
http://clusterlabs.org/quickstart-redhat.html
http://clusterlabs.org/wiki/Install
http://keithtenzer.com/2015/06/22/pacemaker-the-open-source-high-availability-cluster/
http://bigthinkingapplied.com/creating-a-linux-cluster-in-red-hatcentos-7/
https://bigthinkingapplied.com/tag/cluster/
http://www.tokiwinter.com/building-a-highly-available-apache-cluster-on-centos-7/
http://www.cloudera.com/documentation/enterprise/5-4-x/topics/admin_cm_ha_failover.html
http://jensd.be/156/linux/building-a-high-available-failover-cluster-with-pacemaker-corosync-pcs
Documentação Oficial sobre cluster no Red Hat 7:
Documentação geral do Red Hat 7:
https://access.redhat.com/documentation/en/red-hat-enterprise-linux/7/
Bom dia camarada, estou com um problema e talvez você possa me ajudar. Saberia me informar como coloco todos os resources para um nó específico? Porque isso!
Veja a saída do meu comando :
# pcs status
Cluster name: arcconn
Last updated: Mon Apr 11 07:26:59 2016
Last change: Fri Aug 14 11:18:22 2015
Stack: cman
Current DC: node01 – partition with quorum
Version: 1.1.11-97629de
2 Nodes configured
6 Resources configured
Online: [ node01 node02 ]
Full list of resources:
Master/Slave Set: arc_drbd_clone [arc_drbd]
Masters: [ node02 ]
Slaves: [ node01 ]
arc_fs (ocf::heartbeat:Filesystem): Started node02
Resource Group: arc_vip_grp
arc_vip (ocf::heartbeat:IPaddr2): Started node01
arc_vip_src (ocf::heartbeat:IPsrcaddr): Started node01
arc_dummy (ocf::heartbeat:Dummy): Stopped
Failed actions:
arc_fs_start_0 on node01 ‘unknown error’ (1): call=28, status=complete, last-rc-change=’Mon Apr 11 07:26:51 2016′, queued=0ms, exec=73ms
O arc_fs (ocf::heartbeat:Filesystem): Started node02 está no nó “node02” e os outros estão no node01
Onde posso ter errado camarada?
Bom dia, Fred!
Pelo resultado do comando que você enviou, eu não consegui identificar onde está o problema. Entretanto, pensei em algumas coisas para você verificar:
1) Você possui dois recursos para gerenciar o IP do cluster, o arc_vip e o arc_vip_src. Isso é mesmo necessário? As máquinas do cluster possuem 3 placas de rede (uma para o recurso arc_vip, outra para o recurso arc_vip_src e outra para ser o IP fixo e constante da máquina? O cluster que ensino a montar no tutorial usa apenas um recurso para gerenciar o IP do cluster e duas placas de rede em cada máquina (veja a sessão Adicionando o IP do cluster como um recurso).
2) Em relação aos recursos arc_vip e arc_vip_src, as interfaces de rede configurada em cada recurso deve ter o mesmo nome em cada máquina.
3) Na sessão Configurando recurso Postgresql no cluster eu mostrei como configurar o recurso PostgreSQL e DRBD para ser montado na máquina apenas depois que o recurso que gerencia o IP do cluster for iniciado. Isso cria uma relação de dependência entre os recursos. Você chegou a fazer algo semelhante no seu ambiente?
4) Para tirar dúvidas sobre os comandos do cluster, eu sugiro fortemente a leitura dos livros e links mostrados no fim do tutorial. Nos livros é explicado o significado e a importância de cada comando e configuração.
Abraço e fica com Deus.
Opa Amigo, Bom Dia!
Eu segui todos os passos mas quando cheguei nessa parte: pcs cluster auth Maq1 Maq2 da o erro : Error: Unable to communicate with pcsd.
Vc saberia me ajudar?
Boa tarde, André!
Acho que faltou você realizar as instruções citadas na seção: “Configurando os dois nós do cluster para sincronizar a configuração”.
Essa mensagem indica que ele não conseguiu acessar o serviço pscd.
Abraço e fica com Deus. 🙂
Oi, boa tarde…. excelente post…. Em relação ao disco sincronizado pelo drbd, posso usar um LV ou tem que ser o disco raw mesmo(/dev/sdb)?
Boa tarde, Fabrício!
Nunca usei DRBD com LVM… eu não indicaria este tipo de uso, pois há sérias chances de perda de dados caso a sincronização dos discos via rede falhe.
Já ocorreu falha de sincronização no ambiente de produção e precisei iniciar a sincronização novamente para evitar perda de dados caso ocorresse a necessidade de chavear para o outro servidor… não foi simples fazer o throubleshooting e voltar ao normal…
Hoje não trabalho mais com ambientes on-promisse, mas fica a dica.